

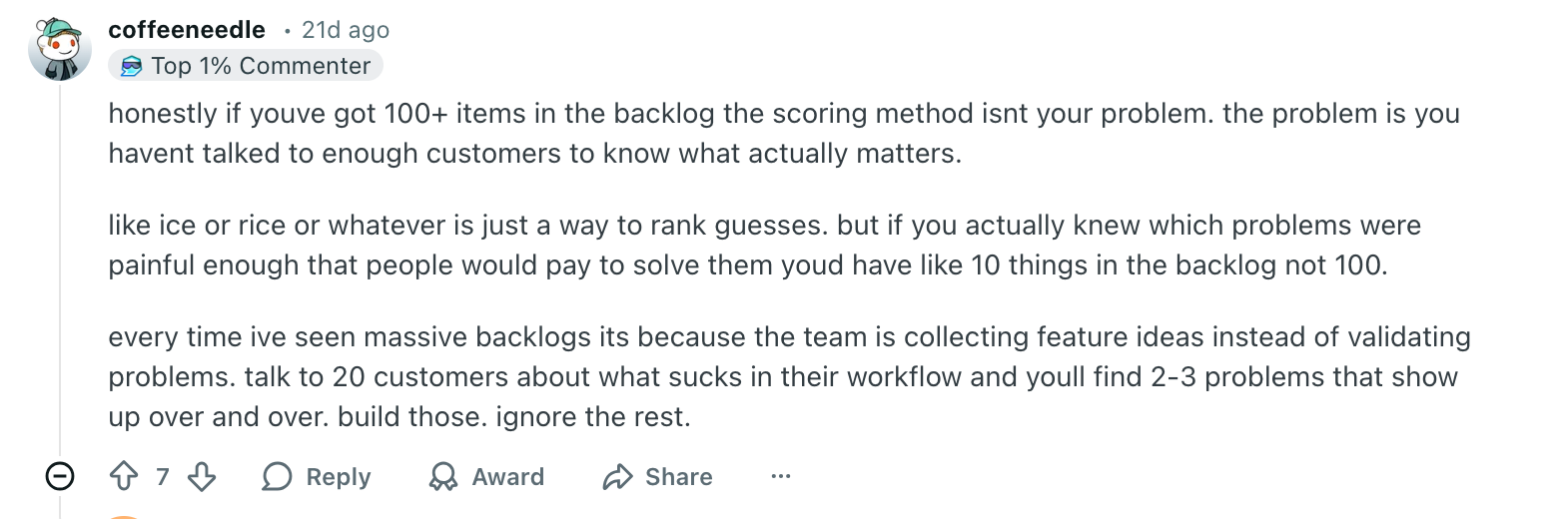
Feature prioritization starts to feel like guesswork when every signal says something different. The backlog is full, the frameworks are ready, and the decision still comes down to assumptions dressed up as process.
That is usually the real problem: just not enough clear customer input when it matters most. A scoring model can sort options, but it cannot tell a team what customers actually need or why the same request keeps coming back.
When there is a steady flow of real customer conversations, the decision gets clearer. This article looks at why feature prioritization feels so subjective, where the usual inputs fall short, and how continuous interview-based insight can make product decisions feel far more grounded.
Why Feature Prioritization Feels Harder Than It Should
The frameworks are not the problem
RICE, MoSCoW, and simple impact-effort models are not the enemy. They exist for a good reason. RICE gives teams a way to weigh Reach, Impact, Confidence, and Effort, while MoSCoW helps sort work into Must-haves, Should-haves, Could-haves, and Won’t-haves. That kind of structure matters, especially when too many requests are competing at once.
Where it gets messy
The trouble starts when the framework shows up before the customer evidence does. Teams end up scoring assumptions instead of signals. “Reach” becomes an estimate, “Impact” becomes a hunch, and “Importance” quietly turns into whatever sounded most urgent in the last meeting.
A framework can organize the conversation, but it cannot create certainty on its own. It can help compare options. It cannot fill in the missing picture of what customers are actually struggling with.
Why smart teams still go in circles
That is why even capable teams can spend a lot of time prioritizing and still leave the room unconvinced. The process looks structured, but the structure is sitting on top of shaky inputs. In a recent r/ProductManagement thread, one PM asked: “How to effectively prioritise a product backlog? ICE or RICE alternatives.” The entire conversation here is basically practitioners admitting that the framework is rarely the real issue. ”
It captures the bigger customer truth that frameworks can rank options, while customer conversations are what create deep customer understanding for prioritization in the first place.
Before looking at the scoring itself, it helps to see what each common input adds, and where it starts to fail.
Why Frameworks Still Feel Subjective in Real Teams
The framework gives structure. It does not guarantee certainty.
In real planning meetings, RICE’s numbers are not always grounded enough.
- Reach can be a rough forecast rather than a measured pattern.
- Impact can mean adoption, retention, revenue, satisfaction, or just a strong internal belief.
- Confidence helps signal uncertainty, but it still depends on honest judgment.
- Effort is often the only input the team feels relatively sure about.
Product School’s 2025 prioritization guide makes this visible in a practical way: it defines reach as how many customers will be affected in a given period, and impact as the expected effect on the goal you are trying to move. It also notes that, even with confidence built in, there are still a lot of uncertainties in RICE.
The debate shifts from the customer problem to the score.
Once the inputs are loose, the conversation starts circling the numbers instead of the need underneath them. Teams spend time debating whether something is a 2 or a 3, while the actual customer problem stays only half-defined.
MoSCoW runs into the same basic limit in a different shape. Atlassian’s current framework guide notes that criteria for a “must have” versus a “should have” can be hard to pin down, and if stakeholders do not agree, prioritization becomes ineffective and subjective.
What this really creates
What it creates is false confidence.
- The score looks precise.
- The ranking looks settled.
- The evidence underneath is still shaky.
The best defense in prioritization is not a prettier scoring model. It is a defensible list built from real customer problems. Once the team is working on repeated issues that customers actually care about, the debate gets smaller because the evidence is stronger.
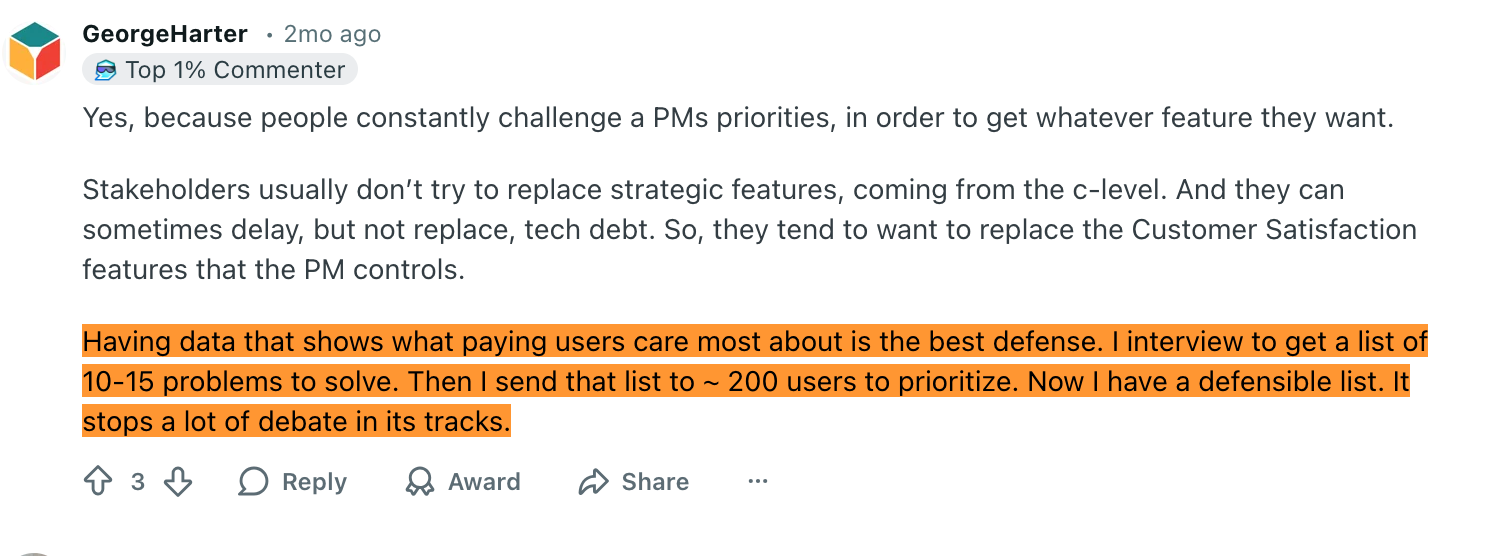
Before Better Prioritization, Better Collection
Before teams score the wrong thing, they usually collect the wrong way. Requests are spread across Slack, sales calls, support tickets, docs, DMs, and scattered notes, so whatever gets remembered most easily starts to look most important. That makes prioritization reactive. Teams end up building for the most visible request, not the strongest recurring problem.
Productboard’s current guidance makes the same point in a more polished way: the first step is to centralize all product requests and feedback in one place, then identify trends and link insights to feature ideas so decisions are based on patterns rather than scattered noise.
Before you score a feature, ask:
- Is this a repeated problem or just a recent request?
- Do we have multiple examples, not one anecdote?
- Is this the actual need, or only the customer’s proposed fix?
- Did this come from one loud account or a real pattern across users?
That is the real starting point, because once the inputs are cleaner, the next question becomes much more useful: what does stronger customer evidence actually look like before a team decides what to build?
What Better Customer Evidence Looks Like Before You Prioritize
The way out of guesswork is not a longer meeting or a stricter scoring ritual. It is better customer evidence. Not more of it in the abstract, but the kind that makes a decision clearer before the team starts ranking options.
That usually means getting closer to the problem behind the request, not just the request itself. A feature request can be useful, but it is still a suggestion for a solution. It does not automatically tell you what is broken, who is feeling it most, or how often it is actually getting in the way. This is often where surveys fall short when teams rely only on summarized feedback instead of deeper conversations.
What teams actually need to know
Before making a feature prioritization call, teams need a clearer view of a few things:
- What is the actual problem behind the request?
- Who is affected most?
- How often does it happen?
- What workaround are users using now?
- How urgent is it really?
- What words do users use when they describe the friction?
That last part matters more than it seems. Clear wording from users often tells you whether the issue is a minor annoyance, repeated friction, or something serious enough that people are already changing behavior to work around it.
What practitioners keep saying
This shows up very clearly in PM discussions, too. In one r/ProductManagement thread 2 years ago, a commenter made the stronger point underneath all of this:
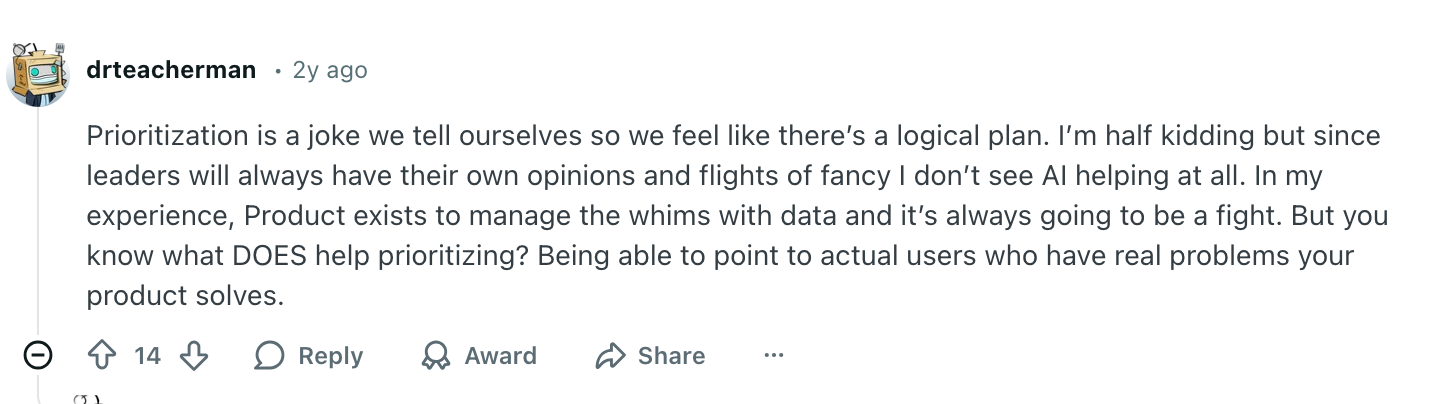
A quick way to see the gap
That is the missing input in most prioritization systems. Direct, structured customer evidence that explains the need behind the request. And once that becomes the standard, the next question is practical: how do you keep gathering that kind of evidence often enough for it to be useful? That is where continuous AI interviews start to matter.
Where Continuous AI Interviews Fit Into Feature Prioritization
AI interviewers become useful here not because they prioritize for a team, and not because they remove judgment — but because they improve the quality and continuity of the customer evidence going into the decision. That is the real role here. The framework can still rank the work. What changes is that the team is no longer relying so heavily on memory, recency, or secondhand summaries. That is where an AI interviewer like Frank fits in։
📌What is Frank?Frank is an always-on AI interviewer that runs in-depth interviews at scale, asks follow-up questions in real time, and turns customer conversations into searchable, decision-ready insight. It works especially well for feature discovery — interviewing users right after they interact with a feature, or when they don't.
Why one-off interviews are not enough
Manual customer interviews still matter, but they are easy to delay, hard to scale, and difficult to keep consistent when the backlog is moving fast. Teams know they should talk to customers more often than they do. The problem is usually not intent. It is time, coordination, and the fact that by the time the next round of interviews happens, the roadmap conversation has already moved on.
What this changes in practice
A continuous AI interviewer makes it easier to keep structured customer conversations running in the background of normal product work. That works best, however, when those conversations are guided by a useful framework for asking better questions. That gives teams a steadier stream of usable input to work from, including:
- current interview transcripts
- repeated objections
- recurring motivations
- tagged themes over time
- sourced answers tied back to actual conversations
That kind of evidence is much more useful in feature prioritization than a vague summary or a half-remembered sales call. It gives the team something concrete to work with: what problem keeps repeating, who is affected, and what users are trying instead.
Frank fits here perfectly because it gives teams a more consistent body of customer evidence to work from during prioritization. Instead of relying on scattered feedback, internal assumptions, or the loudest recent opinion, they can come back to a clearer record of real customer signals.
A Spreadsheet Cannot Interview a Customer
Feature prioritization gets much less dramatic once a team stops expecting a framework to perform miracles. A scoring model can sort the work. It cannot explain what customers actually need, or why the same problem keeps coming back.
The fix should be that better prioritization comes from better evidence. Clearer customer input. Repeated patterns. Enough real context to tell the difference between a real problem and a very persuasive anecdote.
And that is where Frank earns its spot: not as the thing making the decision, but as the thing helping the team stop pretending that memory, momentum, and last week’s loudest opinion count as evidence.

FAQ
What is the best framework for feature prioritization?
There is no single best one. A framework helps organize decisions, but the quality of the decision still depends on the quality of the input.
Why does feature prioritization still feel subjective?
Because teams often score assumptions, incomplete feedback, or internal opinions instead of clear customer evidence.
Should customer requests decide the roadmap?
No. Requests are useful signals, but they are often suggested solutions, not the underlying problem.
What is the biggest mistake teams make in prioritization?
They debate the score before they understand the customer problem behind it.
Why are feature requests not enough on their own?
Because they show what someone asked for, not why they asked for it, how often the issue happens, or how important it really is.
What makes customer interviews useful in prioritization?
They add context. They show what is actually happening, who is affected, and what keeps repeating across real conversations.
Where do AI interviews help most?
They help when teams need a steady flow of structured customer input, so decisions are based on current evidence instead of memory or recency.


.jpg)